
As a data scientist, I understand the importance of building a machine learning pipeline. A machine learning pipeline is a sequence of steps that are taken to transform raw data into a model that can be used for predictions. The pipeline is used to automate the process of training, testing, and deploying models.
Table of Contents
In this article, I will be discussing the benefits of using a machine learning pipeline, the components of a pipeline, pipeline architecture, common models, and how to create a pipeline using Azure Machine Learning, AWS Machine Learning, and Spark ML. I will also provide examples of deep learning pipelines and best practices for building and maintaining machine learning pipelines.
Benefits of Using Machine Learning Pipelines
There are several benefits of using machine learning pipelines. First, it automates the process of data cleaning, feature extraction, and model training. It also allows for the reuse of code, which can save time and reduce errors.
Machine learning pipelines also enable collaboration among team members, as it provides a standardized process for data processing and model building. Additionally, pipelines can be easily updated to accommodate changes in the data or model.
Understanding the Components of a Machine Learning Pipeline

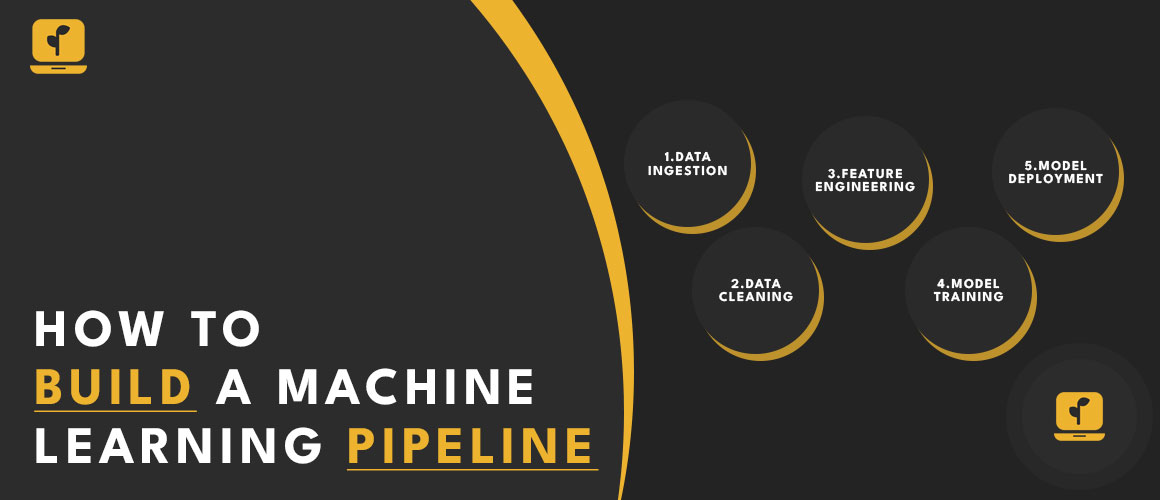
A machine learning pipeline consists of several components. The first component is data ingestion, where raw data is collected and stored. The next component is data cleaning, where the data is preprocessed to remove any irrelevant information or errors.
Feature engineering is the next step, where the data is transformed into features that can be used for model training. The fourth component is model training, where the machine learning algorithm is applied to the data to generate a model. The final component is model deployment, where the model is used for predictions.
Machine Learning Pipeline Architecture
The architecture of a machine learning pipeline is dependent on the specific use case. However, there are some common patterns that can be used. The first pattern is a linear pipeline, where the data flows through each component in a sequential order.
The second pattern is a branching pipeline, where the data is split into multiple paths and processed in parallel. The third pattern is a feedback pipeline, where the output of the model is used to adjust the input data.
Common Machine Learning Pipeline Models
There are several common machine learning pipeline models that are used in industry. The first model is the batch processing model, where large datasets are processed in batches. The second model is the real-time processing model, where data is processed in real-time. The third model is the streaming processing model, where data is continuously processed as it comes in.
Creating a Machine Learning Pipeline using Azure Machine Learning

Azure Machine Learning is a cloud-based platform that can be used to create machine learning pipelines. The first step is to create a workspace, where the pipeline will be developed. Next, data sources are added to the workspace. Once the data is added, the pipeline can be created using the drag-and-drop interface. Azure Machine Learning also provides pre-built components that can be used in the pipeline.
Creating a Machine Learning Pipeline using Spark ML

Spark ML is an open-source platform that can be used to create machine learning pipelines. The first step is to create a Spark session, where the pipeline will be developed. Next, data sources are added to the session. Once the data is added, the pipeline can be created using the Spark ML API. Spark ML also provides pre-built components that can be used in the pipeline.
Examples of Deep Learning Pipelines
Deep learning pipelines are used for complex tasks such as image recognition and natural language processing. One example of a deep learning pipeline is a convolutional neural network (CNN) for image recognition. The pipeline consists of several layers of convolutional and pooling layers, followed by a fully connected layer for classification.
Another example of a deep learning pipeline is a recurrent neural network (RNN) for natural language processing. The pipeline consists of several layers of LSTM cells, followed by a fully connected layer for classification.
Training and Deploying a Machine Learning Pipeline
Once the machine learning pipeline is created, it needs to be trained and deployed. The training process involves feeding the data into the pipeline and adjusting the model parameters to optimize performance. The deployment process involves using the trained model to make predictions on new data. The pipeline can be deployed on a local machine, a cloud-based platform, or a containerized environment.
Best Practices for Building and Maintaining Machine Learning Pipelines
There are several best practices for building and maintaining machine learning pipelines. First, it is important to document the pipeline, including the data sources, data cleaning steps, and model parameters. Second, it is important to test the pipeline with different datasets to ensure it is robust. Third, it is important to monitor the pipeline for errors and performance issues. Fourth, it is important to update the pipeline as the data or model changes.
Tools and Services for Machine Learning Pipeline Development
There are several tools and services for machine learning pipeline development. Azure ML pipeline, AWS ML pipeline, and Databricks pipeline are cloud-based platforms that provide drag-and-drop interfaces for building machine learning pipelines. These platforms also provide pre-built components that can be used in the pipeline. Other tools such as Kubeflow and MLflow provide more flexible and customizable options for pipeline development.
Conclusion and Next Steps for Building Your Own Machine Learning Pipeline
In conclusion, building a machine learning pipeline is an important step in automating the process of model training and deployment. There are several benefits to using a pipeline, including time savings, error reduction, and collaboration among team members. Understanding the components of a pipeline and the common pipeline models is essential for building an effective pipeline.
Azure Machine Learning, AWS Machine Learning, and Spark ML are all powerful tools that can be used to create machine learning pipelines. Additionally, following best practices for building and maintaining pipelines is important for ensuring the pipeline is robust and effective.






